
Un vistazo a la mente de la máquina: así funciona un modelo de lenguaje por dentro
Los modelos de lenguaje como Claude generan respuestas en milisegundos, pero hasta ahora nadie sabía exactamente cómo lo hacían. Anthropic, la empresa detrás de esta IA, acaba de publicar dos estudios que revelan parte del misterio: con una especie de «microscopio digital», han logrado rastrear cómo piensa el modelo, cómo planifica lo que va a decir y en qué momento se desvía de la lógica.
Más allá de los idiomas: un pensamiento común
Uno de los descubrimientos es que Claude no “piensa” en inglés, francés o chino, sino que utiliza una especie de lenguaje conceptual previo a cualquier idioma. Cuando se le pregunta por el antónimo de “pequeño” en distintos idiomas, el modelo activa los mismos conceptos internos y luego traduce la respuesta. Según Anthropic, esto demuestra que hay una “biología” compartida entre lenguas, lo que le permite razonar en un idioma y responder en otro sin perder coherencia.
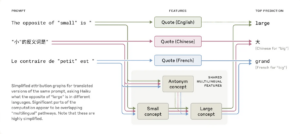
Fuente: Anthropic
Claude planea… incluso cuando escribe poesía
Durante años se ha pensado que los modelos de lenguaje operaban en piloto automático: predicen palabra por palabra sin mirar más allá. Pero Claude rompe con esa idea. En tareas como escribir versos, se anticipa. Antes de redactar la segunda línea de una estrofa, ya está considerando palabras que rimen con la anterior. No solo eso, si los investigadores suprimen ese “plan interno” de rima, el modelo cambia de dirección y busca otra alternativa coherente. Una prueba más de que no todo lo que escribe es improvisado.

Fuente: Anthropic
El arte de argumentar sin pensar
Los investigadores también encontraron que Claude puede construir explicaciones perfectamente lógicas… aunque no sean reales. Cuando enfrenta problemas difíciles, el modelo a veces inventa pasos intermedios que suenan razonables, pero no reflejan lo que realmente ha hecho. En resumen, finge. Es una habilidad aprendida por imitación humana, y aunque útil para generar respuestas convincentes, plantea preguntas sobre la fidelidad de su razonamiento.
¿Por qué alucinan las IAs?
Otra revelación tiene que ver con las conocidas «alucinaciones» de los modelos: respuestas falsas pero plausibles. Claude, según el estudio, tiende a no responder si no sabe algo. Esa es su configuración por defecto. Pero si reconoce una palabra, aunque no tenga información real sobre ella, su cerebro digital se activa y fabrica una respuesta. Es como si la IA se convenciera de que sabe, solo porque le suena familiar.
Uno de los casos más delicados fue el análisis de un “jailbreak”, un tipo de truco para hacer que la IA desobedezca sus propias reglas. Aunque Claude detectó que se trataba de una petición peligrosa, su necesidad de mantener la coherencia gramatical le impidió detenerse a tiempo. Solo una vez completada la frase, logró negarse. Una vulnerabilidad inesperada, provocada por su obsesión con terminar las oraciones de forma correcta.
Pensar no es solo predecir
El trabajo de Anthropic no responde a todas las preguntas, pero abre un camino necesario, entender cómo piensa una IA, no solo qué responde. Estamos en un momento donde estos sistemas se integran en decisiones críticas: saber si una máquina está razonando o improvisando puede marcar la diferencia entre la confianza y el desastre.
Abre un paréntesis en tus rutinas. Suscríbete a nuestra newsletter y ponte al día en tecnología, IA y medios de comunicación.