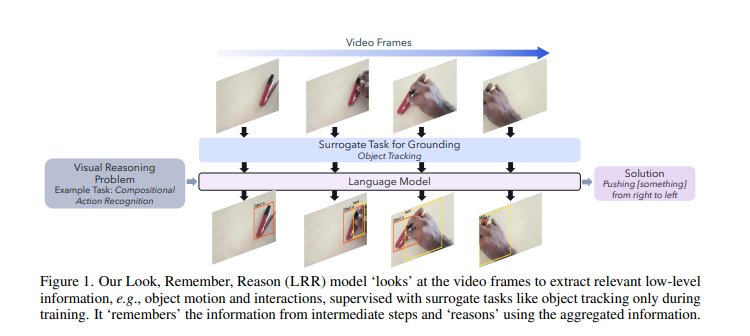
Qualcomm AI Research ha presentado un avance significativo en el campo de la inteligencia artificial con el desarrollo de LRR (Look, Remember, Reason), un modelo de lenguaje multimodal diseñado para tareas complejas de razonamiento visual. Este modelo, que utiliza un enfoque de Mirar, Recordar, Razonar, se destaca por su codificador de video de dos flujos con atención espacio-temporal, lo que le permite sobresalir en tareas de razonamiento de video al superar los métodos específicos de tareas.
La investigación, detallada en MarkTechPost, destaca cómo el LRR mejora las habilidades visuales de baja nivel en modelos de lenguaje, un área que hasta ahora no había sido plenamente explorada o demostrada en modelos multimodales actuales. Estos modelos, aunque excelentes en diversas áreas, aún no habían demostrado su eficacia en tareas que requieren una atención detallada a detalles finos de baja nivel junto con un razonamiento avanzado.
El nuevo modelo LRR de Qualcomm AI Research promete mejorar significativamente las habilidades visuales de baja nivel en los modelos de lenguaje, superando los métodos específicos de tareas en el razonamiento de video.
El LRR se entrena de extremo a extremo en tareas como la detección y seguimiento de objetos, empleando un proceso de ‘Mirar, Recordar, Razonar’ que le permite capturar tanto señales estáticas como basadas en movimiento en videos a través de un codificador de video de dos flujos con atención espacio-temporal. Este enfoque ha llevado al LRR a liderar la tabla de clasificación del desafío STAR a partir de enero de 2024, demostrando su rendimiento superior en el razonamiento de video.
El modelo ha sido entrenado en diversos conjuntos de datos como ACRE, CATER y Something-Else, mostrando su versatilidad y eficacia en la interpretación de señales visuales de baja nivel. La capacidad del LRR para ser entrenado de extremo a extremo y superar métodos específicos de tareas subraya su potencial para mejorar el razonamiento de video.
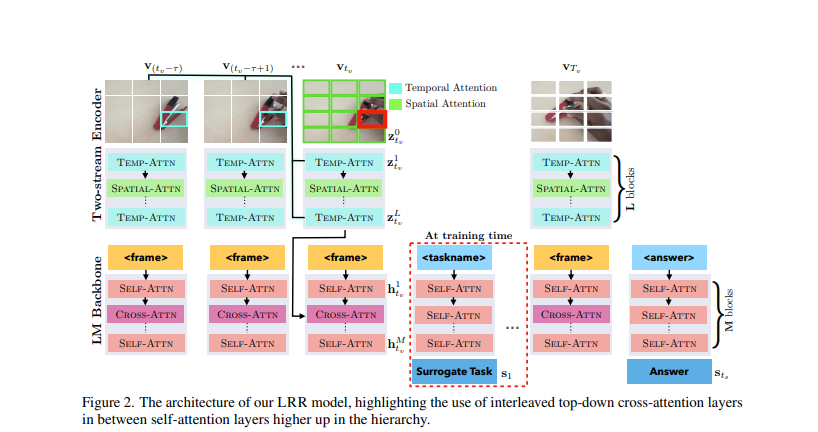
El marco LRR sigue un proceso de tres pasos donde la información visual se extrae utilizando habilidades gráficas de baja nivel y se integra para llegar a una respuesta final. Este enfoque permite al LRR capturar efectivamente señales estáticas y basadas en movimiento en videos, lo que podría abrir nuevas posibilidades para su aplicación en una gama más amplia de tareas de razonamiento visual y conjuntos de datos.
Suscríbete a nuestra newsletter y ponte al día en tecnología, IA y medios de comunicación.