
En el campo de la inteligencia artificial, una alucinación se refiere a una respuesta que es disonante, errónea o fuera de contexto ante una solicitud específica. Identificar cuándo nuestra IA está alucinando puede ser muy evidente en algunos casos, mientras que en otros puede ser un gran desafío. Para minimizar su aparición, es esencial comprender cómo «razona» nuestro modelo.
Spoiler: Los modelos de IA no razonan como los humanos; operan basándose en patrones estadísticos y probabilidades aprendidas de los datos de entrenamiento.
Los modelos con arquitectura transformer, como ChatGPT (Chat Generative Pre-trained Transformer), generan texto a través de unidades llamadas tokens. Un token es la unidad mínima de texto que el modelo procesa. Puede ser una palabra completa, parte de una palabra o incluso signos de puntuación y espacios, dependiendo del método de tokenización utilizado, como el Byte Pair Encoding (BPE).
Después de analizar el texto de entrada, el modelo establece relaciones entre los tokens para predecir el siguiente token. Utiliza el contexto acumulado para generar cada nuevo token, actualizando continuamente el contexto hasta formar frases y párrafos coherentes.
Es importante entender que nuestro modelo no comprende el significado de las palabras como lo hacemos nosotros; procesa y genera texto basándose en patrones estadísticos aprendidos de grandes conjuntos de datos. Los tokens son secuencias de caracteres que el modelo utiliza para predecir el siguiente elemento en una secuencia, sin una comprensión inherente del contexto o el contenido semántico.
Bajemos a tierra todos estos conceptos con un ejemplo. Imagina que escribimos a nuestro modelo la frase: «El cielo está…». El modelo tokeniza esta frase y, basándose en el contexto y en los patrones aprendidos, genera una lista de posibles respuestas, como nublado, despejado, oscuro, lleno, guitarra, etc. Cada opción tiene una puntuación asociada, conocida como logit, que refleja la probabilidad relativa de que un token sea el seleccionado para completar nuestra frase. Esta selección depende del entrenamiento del modelo. De ahí la importancia de evitar los sesgos durante todo el proceso.
Aquí es donde entra en juego un parámetro fundamental: la temperatura.
La temperatura es un parámetro que podemos ajustar para modificar la distribución de probabilidades de respuesta. Dicho de otra forma, modifica la aleatoriedad y creatividad en las respuestas del modelo.
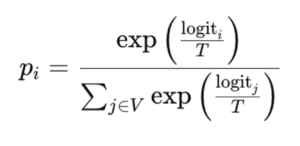 donde T es la temperatura.
donde T es la temperatura.
La fórmula puede asustar, pero viene a decir que una temperatura baja concentra la probabilidad en los tokens con logits más altos (es decir, aquellos que son más probables: nublado, soleado..), haciendo que el modelo sea más conservador. Una temperatura alta distribuye la probabilidad de manera más uniforme entre los tokens posibles, disminuyendo la distancia entre la posibilidad que sea un token u otro, aumentando así la aleatoriedad.
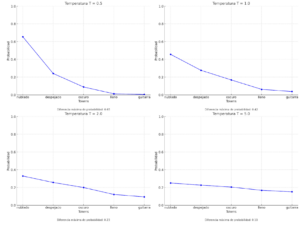
– Temperatura baja (T → 0): El modelo es más determinista y preciso en sus respuestas, reflejando un pensamiento analítico y racional.
– Temperatura alta (T → 1 o mayor): El modelo es más aleatorio y diverso en sus respuestas, promoviendo un pensamiento creativo y divergente.
Las respuestas menos probables y, por ende, menos deterministas, pueden considerarse más creativas. Esto es útil para tareas que buscan innovación, inspiración y explorar caminos menos transitados. Si, por el contrario, necesitamos contenido más factual, estricto y preciso, debemos reducir la temperatura del modelo, ya sea para generar texto, imágenes o videos.
Esta forma de modelar la creatividad plantea nuevos debates sobre su definición y la capacidad de la IA para ejercerla. ¿Son las respuestas menos probables más creativas? ¿Podemos modelizar el pensamiento divergente como aquel menos determinista? Son reflexiones como estas las que marcarán el carácter y las capacidades a futuro de lo que sin duda, serán nuestros asistentes personales.
Las grandes tecnológicas buscan minimizar las alucinaciones porque pueden llevar a respuestas incorrectas o engañosas, lo que presenta riesgos legales y éticos. Sin embargo, las alucinaciones también pueden ser vistas como una oportunidad. Son parte del comportamiento emergente del modelo que, si se canaliza adecuadamente, puede inspirar nuevas ideas y enfoques.
Las alucinaciones son necesarias. Son parte del libre albedrío que posee nuestro modelo. Si las gestionamos de manera positiva y conseguimos hacer de este aspecto un pro y no un contra, podemos darle un nuevo uso a nuestro modelo y conocer límites hasta ahora sin descubrir porque, lo queramos o no, tenemos nuestros propios sesgos lo que nos impide muchas veces ver más allá de lo evidente.
Gracias a los márgenes difusos que generan las alucinaciones, podemos descubrir nuevos caminos en todas las áreas del conocimiento. Nuevas proteínas, nuevas formas de relacionar datos, nuevas formas de creación artística o nuevas formas de entender la realidad.
Abre un paréntesis en tus rutinas. Suscríbete a nuestra newsletter y ponte al día en tecnología, IA y medios de comunicación.